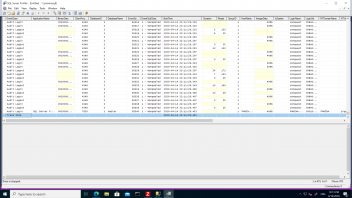
Hi Marcel, I'm sure it's each image, please see the SQL profiler image at my original post (Apr 15th 2020). There are logins/logouts every as low as <20 milliseconds
Posts by enpq
-
-
Hi Marcel, I don't want to mix things, but this issue reminds me a problem I have seen after the recent update of my installation. The topic is "repeated login to SQL", and the culprit was the lsss process. To quote myself, " I found that dgate64 logins and logout from SQL for each image. Apparently, the vast majority of time is used to do these continuos logins, that seem to tax lsass and cause unneded delays. I wonder if these logins for each image are needed. Couldn't be kept logged-in the proces, at least for some minutes?"
The issue remained unresolved, and I relaize just now that you actually replied to my last post and I did not notice it.
If this is the same issue, I'm still available to do testing.
-
Hi Marcel, sorry for m late reply, I missed your post.
Yes, I'm wlling to test any beta relaease you find useful.
In my setup the most offending operations are plain transfers (eg from the scanner, or from another conquest instance). The transfer is fast enough to keep up with two scanners working simultaneously in high troughput mode (multiband fMRI etc.), but no room for problems creating a backlog, or for more scanner. It is odd considering that less than 20% of resources are used.
I played with the various ODBC drivers, and the problem (ie a new SQL login for each image) is there with any driver supporting pooling.
Best, federico
-
Hi Marcel, I'll look a bit in the ODBCI code. Meanwhile, I'm playing with the various ODBC drivers, because it looks like not all have support for pooling
-
Hello, I'm at the stage of porting the data from old (SQL2005+conquest 1.4...) to new (SQL 2019+conquest 1.5) platform, and I found a stange behaviour that apparently hampers the performences with MsSQL.
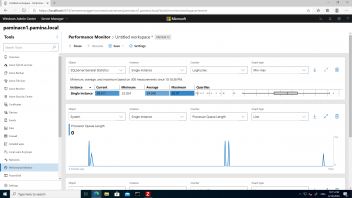
If I transfer the images from another instance, or put them in the "incoming" folder, the current setup imports around 50 img/s. However, I noticed that the hardware is barely used: processsors around 20%, processor queue 0, disk queue 0 (see attachments, the hardware is old but capable: 2x 4 cores xeon, SAN based on 15k disks). I noticed that during import the lsass process uses as many as resources as sql+conquest together. I investigated a bit the issue, and I found that dgate64 logins and logout from SQL for each image. Apparently, the vast majority of time is used to do these continuos logins, that seem to tax lsass and cause unneded delays. I wonder if these logins for each image are needed. Couldn't be kept logged-in the proces, at leas for some minutes?
Interestingly, if the database is regenerated (dgate64 -ARMAG0) a single login is performed and all the images are imported under the same connection to SQL, at an incommensurably higher speed. I understand that in this case no disk write is implied, but it looks like it is not the disk the bottleneck. This is also suggested by the fact that remote transfer (implying full disk write) and data in "incoming" (implying only a move between directories in the same partition) hve similar speeds of 40-60 img/s.
BTW the documentation looks to suggest that pooled logins are faster tahn unpooled ones, and teh logins are of the unpooled variety.
Best, Federico
-
Hello, I did further testings, and I couldn't confirm the behaviour... Indeed, now the symbolik link seems to work. Moreover, I deliberately pointed the link to a non-existant target, and in this case dgate64 complains in the pacstrouble.log about the missing file, but does not crash... I'll do further testing
-
Hello:
OLD: Hyper-V VM, windows 2016 core + SQL 2016, Conquest 1.4.19b (64 bit)
NEW: physical servers, Windows 2016 core+ SQL 2019, Conquest 1.5 (64 bit)
in the old (testing) platform symbolic links (mklink dgate.dic \\UNC\target) work for all configuration files, in the new platform they work for all files, but dgate.dic
BTW, installation on windows core (gui-less) 64 bit failover cluster has some hitches, as soon as I'll finish the transition from the old platform (windows 2003+ SQL 2005 32 bit) I'll write some info/howto that can be useful for others attempting the came configuratom
-
Hello Marcel, we have now used conquest for many years in our research-oriented environment, thank you!
We have a conquest instance in a failover cluster configuration. For ease of management, I moved all configuration files (dicom.ini, dgatesop.lst, dicom.sql, acrnema.map, dgate.dic) to a share on the cluster, and I made symbolic links to them in the installation directories. This used to work, however I recently updated to verison 1.5 and now dgate64 complains that it can't find dgate.dic and crashes (no problem with the other files). I guess that some kind of check on the file was introduced or changed in the new release. Note that in this case I can't make a hard link because the target is in a UNC share. I would ask, if possible, to revert this behaviour, and especially to avoid changing the behaviour for the other config files, that I change more often because of researcher's needs.
Thnak you again,
Federico
-
Hi Marcel, thank you for your help.
We'll do our test with lua (until now we directly invoked cmd)
to reply to your questions:
-no, it is not a log issue. Indeed, the command lines are all logged, what happens is that they are not actually executed
-the series are dropped at random, ie transferring again the same patient, dropped series are different.We'll let you know the result of our tests.
Best, Federico
-
Hi Marcel and thank you for your support.
Starting from the second issue:
we tried to use an ImportConverter, but the behaviour is the same: ie the process line is sent to the log, but it is not always executded, in ana apprently random way. Any suggestion about how to debug this issue?
Regarding the first issue, I would have a further report and a suggestion
-the report is that if the 'after' clause is not provided, the command is not triggered at all, irrespectively of the "ForwardCollectDelay" value
-the suggestion is to change the "after" timeout logic. If I understood correctly, the timeout is triggered by the first image, and then commands are queued serially every "timeout" seconds if timeout is shorter than transmission time. In my opinion, it would be more useful if the timeout is started by the first image, but then it is reset by each incoming image that does not change the text in
process (command) patientID seriesuid
This way, the command would be issued only if the timeout expires, ie it is not reset. This occur logically only if time between successive images is longer than timeout, or after the last image.
On my oipinion this logic is safer, because "timeout" would be compared to the transmission time of a single image, that is generally much more predictable of the transmission time of a whole series. In our environment, we have seies made by thousand of images, so with the current logic we would be forced to set a very long timeout, that would unnecessarily slow the forwarding process for short series (including 3-50 images)
Thank you again, Federico
-
Dear Marcel,
I'm trying to start a home-made conversion tool using an exportconverter in dicom.ini
In my development environment I'm sending patients from another conquest installation. I have a couple of issues with exportconverters (last version, 19b).-we want to start our tool once the series transmission is ended. We are using a command like:
ExportConverter0 = process series after N by cmd /C echo %%time%% >> c:\log.txt
Apparently, the command is not triggered N seconds after series has been transmitted, but every N seconds during the whole transmission. Ie, if N=1 and transmission lasts 20 seconds, we find 20 lines in log.txt, each one 1 second apart from the previous. Our understanding is that an internal timeout (possibly ForwardCollectDelay) would determine if the transmission is finished, then N seconds are waited and the "process" statement is executed. Isn't that the logic?
- the second issue is even more puzzling, because it is apparently random. We increased N in the above exportconverter to 600, that is far higher than transmission time of a series, and we found that apparently only some series are forwarded to the "process" program (in our case, we find 10 or 12 lines in c:\log.txt, while a patient with 16 series has been correctly transmitted). The patient is correctly received, ie all 16 series are stored and included in db. The expoortconverter lines are all present in the conquest log. Then, we went back to N=1 s and we found that the problem is present also in that case, ie some series are forwarded to process every N seconds, while some other are never forwarded. Thus, it appears that some series get "lost". Finally, increasing QueueSize from 128 to 256 or even 2560 does not improve (or even mare worst) the issues.
Thank you in advance for your help
-
Hi Marcel
I have turned off the "Storage commitment" option on the Philips scanner.
From first tests seems to work fine. In the next days we'll do other tests.
I will keep you updated.Fabio
-
Hi,
it's past a bit of time... Have you some new ideas about the my old problem.
I'll send you again the messages log of PacsTrouble.log and serverstatus.log:
20160909 15:29:42 Inconsistent StudyModal in DICOMStudies: PatientID = '00109677' StudyInsta = '1.3.76.13.71888.2.20160823153122.636850.1', Old='MR', New='PR\MR'
20160909 15:30:13 *** connection terminated
20160909 15:30:22 *** connection terminated
20160909 15:30:31 *** connection terminated
20160909 15:30:40 *** connection terminated09/09/2016 15.30.13 [FUSIONDCM3] UPACS THREAD 8: STARTED AT: Fri Sep 09 15:30:09 2016 (Fabio nel fine PacsTrouble.log: 20160909 15:30:13 *** connection terminated)
09/09/2016 15.30.13 [FUSIONDCM3] *** connection terminated
09/09/2016 15.30.13 [FUSIONDCM3] UPACS THREAD 8: ENDED AT: Fri Sep 09 15:30:13 2016
09/09/2016 15.30.13 [FUSIONDCM3] UPACS THREAD 8: TOTAL RUNNING TIME: 4 SECONDS
09/09/2016 15.30.22 [FUSIONDCM3]09/09/2016 15.30.22 [FUSIONDCM3] UPACS THREAD 9: STARTED AT: Fri Sep 09 15:30:18 2016 (Fabio nel fine PacsTrouble.log: 20160909 15:30:22 *** connection terminated)
09/09/2016 15.30.22 [FUSIONDCM3] *** connection terminated
09/09/2016 15.30.22 [FUSIONDCM3] UPACS THREAD 9: ENDED AT: Fri Sep 09 15:30:22 2016
09/09/2016 15.30.22 [FUSIONDCM3] UPACS THREAD 9: TOTAL RUNNING TIME: 4 SECONDS
09/09/2016 15.30.31 [FUSIONDCM3]09/09/2016 15.30.31 [FUSIONDCM3] UPACS THREAD 10: STARTED AT: Fri Sep 09 15:30:27 2016 (Fabio nel fine PacsTrouble.log: 20160909 15:30:31 *** connection terminated)
09/09/2016 15.30.31 [FUSIONDCM3] *** connection terminated
09/09/2016 15.30.31 [FUSIONDCM3] UPACS THREAD 10: ENDED AT: Fri Sep 09 15:30:31 2016
09/09/2016 15.30.31 [FUSIONDCM3] UPACS THREAD 10: TOTAL RUNNING TIME: 4 SECONDS
09/09/2016 15.30.40 [FUSIONDCM3]09/09/2016 15.30.40 [FUSIONDCM3] UPACS THREAD 11: STARTED AT: Fri Sep 09 15:30:36 2016 (Fabio nel fine PacsTrouble.log: 20160909 15:30:40 *** connection terminated)
09/09/2016 15.30.40 [FUSIONDCM3] *** connection terminated
09/09/2016 15.30.40 [FUSIONDCM3] UPACS THREAD 11: ENDED AT: Fri Sep 09 15:30:40 2016
09/09/2016 15.30.40 [FUSIONDCM3] UPACS THREAD 11: TOTAL RUNNING TIME: 4 SECONDS
09/09/2016 15.30.49 [FUSIONDCM3]P.S. Setting the debug level at fourth level I lose the "*** connection terminated" message.
ENPQ
-
Hi, I'm having many troubles with a PHILIPS RM. 2 instances of Conquest are set-up on the same server, one for a Siemens scanner (that has worked fine for many years), and one for a Philips scanner. Configuration is essentially the same, but the Philips CONQUEST is setup serverless and there is one exportconverter.
I get at least 3 recurring problem
1) sometimes the server crashes, especially with large Philips "enhanced" dicoms, with the following log:
20140329 09:58:35 Written file: R:\rawdata\philips\SPALLETTA\00086869\20140319\1.3.76.13.71888.2.20140319175855.564584.1\1.3.46.670589.11.34249.5.0.4396.2014031918405657408\000001_1.3.46.670589.11.34249.5.20.1.1.4396.2014031918405657408.dcm
20140329 09:58:55 ***VR:ReAlloc out of memory allocating 374492160 bytes20140329 09:58:55 ***A fatal error occurred (out of memory) - closing server
2) sometimes the transfer apparently fails at the scanner console, but the data were actually transfered
3) have several "conncetion terminated" errors on the conquest log:
[FUSIONDCM2] 20140328 12:44:09
[FUSIONDCM2] 20140328 12:44:09 UPACS THREAD 16: STARTED AT: Fri Mar 28 12:44:04 2014
[FUSIONDCM2] 20140328 12:44:09 *** connection terminated
[FUSIONDCM2] 20140328 12:44:09 UPACS THREAD 16: ENDED AT: Fri Mar 28 12:44:09 2014
[FUSIONDCM2] 20140328 12:44:09 UPACS THREAD 16: TOTAL RUNNING TIME: 5 SECONDS
[FUSIONDCM2] 20140328 12:44:18
[FUSIONDCM2] 20140328 12:44:18 UPACS THREAD 17: STARTED AT: Fri Mar 28 12:44:13 2014
[FUSIONDCM2] 20140328 12:44:18 *** connection terminated
[FUSIONDCM2] 20140328 12:44:18 UPACS THREAD 17: ENDED AT: Fri Mar 28 12:44:18 2014
[FUSIONDCM2] 20140328 12:44:18 UPACS THREAD 17: TOTAL RUNNING TIME: 5 SECONDS
[FUSIONDCM2] 20140328 12:44:27
[FUSIONDCM2] 20140328 12:44:27 UPACS THREAD 18: STARTED AT: Fri Mar 28 12:44:22 2014
[FUSIONDCM2] 20140328 12:44:27 *** connection terminated
[FUSIONDCM2] 20140328 12:44:27 UPACS THREAD 18: ENDED AT: Fri Mar 28 12:44:27 2014
[FUSIONDCM2] 20140328 12:44:27 UPACS THREAD 18: TOTAL RUNNING TIME: 5 SECONDS
[FUSIONDCM2] 20140328 12:44:36
[FUSIONDCM2] 20140328 12:44:36 UPACS THREAD 19: STARTED AT: Fri Mar 28 12:44:31 2014
[FUSIONDCM2] 20140328 12:44:36 *** connection terminated
[FUSIONDCM2] 20140328 12:44:36 UPACS THREAD 19: ENDED AT: Fri Mar 28 12:44:36 2014
[FUSIONDCM2] 20140328 12:44:36 UPACS THREAD 19: TOTAL RUNNING TIME: 5 SECONDS
[FUSIONDCM2] 20140328 12:44:45
[FUSIONDCM2] 20140328 12:44:45 UPACS THREAD 20: STARTED AT: Fri Mar 28 12:44:40 2014
[FUSIONDCM2] 20140328 12:44:45 *** connection terminated
[FUSIONDCM2] 20140328 12:44:45 UPACS THREAD 20: ENDED AT: Fri Mar 28 12:44:45 2014
[FUSIONDCM2] 20140328 12:44:45 UPACS THREAD 20: TOTAL RUNNING TIME: 5 SECONDS
[FUSIONDCM2] 20140328 12:44:54
[FUSIONDCM2] 20140328 12:44:54 UPACS THREAD 21: STARTED AT: Fri Mar 28 12:44:49 2014
[FUSIONDCM2] 20140328 12:44:54 *** connection terminated
[FUSIONDCM2] 20140328 12:44:54 UPACS THREAD 21: ENDED AT: Fri Mar 28 12:44:54 2014
[FUSIONDCM2] 20140328 12:44:54 UPACS THREAD 21: TOTAL RUNNING TIME: 5 SECONDSI suspect that point 2 & 3 are related. It seems that the scanner opens the channel, than starts building the ehannced dicom (a task cthet can be quite time-consuming, if several images are to be packed), and finally attempts the transfer.
Any hints? I alread increased TCPIPTimeOut to 900
tahnk you, Federico
-
Hi, sorry for the late reply. After some testing, I think that the problem is related to the parser, not to the command line length. In particular, these converters work:
ExportConverter0 = process series after 120 by C:\dcm2nii\cvdcm.bat %P>nul
ExportConverter0 = process series after 120 by cmd /C C:\dcm2nii\cvdcm.bat %P>nulBut this does not work:
ExportConverter0 = process series after 120 by "C:\dcm2nii\cvdcm.bat %P>nul"
best, Federico
-
Hi, after tweaking a bit, it indeed worked also by directly calling a batch file. I think the problem was the commandline length. Perhaps there is a 254 chars limit? Best, Federico
-
Dear Marcel,
thank you for your fast reply. unfortunately, it doesn't work. Even if I set very simple commands like:
ImportConverter0 = process series after 1 by "echo %P > c:\temp\temp.txt" noting happens (I waited well more than 1 minute). Possibly I'm missing something basilar?
best, Federico
-
Hi, I'm trying to setup a serverless system, that should just store the data on disk, and run a script (actually a .bat under windows) that does some things (make directories etc) and than convert DICOMS into a given format (NIFTI). This script should be run after each series has been completely transferred.
Now, I have 2 problems.
1st, and more serious: if I use the syntax:
ImportConverter0 = system "@start C:\dcm2nii\convertdcm.bat %P > nul"
The script in itself works correctly, however it is triggered before the end of each series transmission (apparently before each slice): useless.
If I use the syntax
process series by command "@start C:\dcm2nii\convertdcm.bat %P > nul"
the very same script does not work at all (apparently, it is not started appropriately). Any hints? Which event actually triggers the "proces series" importconverter? are there any other suggested ways to impement this function?
2nd point is related to making the system reliable: eg is it possible to terminate the invoked process after a given time, if not completed?
Best, Federico
-
Sarry for my late reply. files are stored as uncompressed DICOM in both servers. Thanks, Federico
-
Hi, the flow is:
scanner =>conquest1=>conquest2=>processing
conquest1 stores all the data, conquest2 stores a subset that need custom processing. Because of network/firewall issues we cannot send data directrly from scanner to conquest2, nor process the data on conquest1.So, which is the solution? integrate dgate.dic with the due definitions? I assume that I can find them on the scanner?
best, Federico